當我的神經網絡不能很好地泛化時我該怎麼辦?
我正在訓練一個神經網絡並且訓練損失減少了,但驗證損失沒有,或者它減少的比我預期的要少得多,基於非常相似的架構和數據的參考或實驗。我怎樣才能解決這個問題?
至於問題
對於這個問題的啟發,這個問題是有意留下的,以便其他關於如何將神經網絡的泛化誤差降低到已被證明可以達到的水平的問題,可以作為這個問題的副本來關閉。
另請參閱 Meta 上的專用線程:
首先,讓我們提一下*“我的神經網絡不能很好地泛化”是什麼意思,和**“我的神經網絡性能不好”*有什麼區別。
在訓練神經網絡時,您會不斷地在一組稱為訓練集的標記數據上對其進行評估。如果您的模型無法正常工作並且似乎沒有從訓練集中學習,那麼您還沒有泛化問題,請參閱這篇文章。但是,如果您的模型在訓練集上取得了令人滿意的性能,但在以前看不見的數據(例如驗證/測試集)上表現不佳,那麼您確實存在泛化問題。
為什麼你的模型沒有正確泛化?
最重要的部分是理解為什麼你的網絡不能很好地泛化。大容量機器學習模型具有記憶訓練集的能力,這可能導致過度擬合。
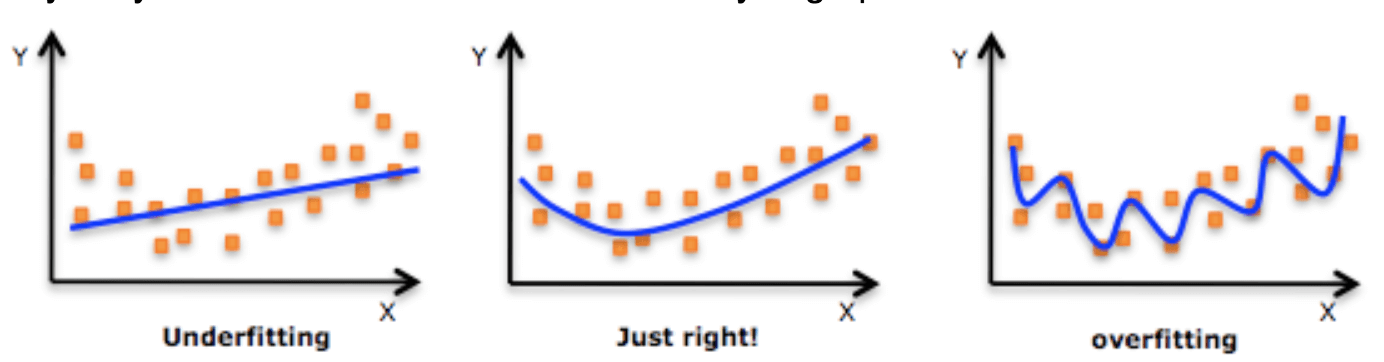
過度擬合是估計器已經開始很好地學習訓練集以至於它已經開始對訓練樣本中的噪聲進行建模(除了所有有用的關係)的狀態。
例如,在下圖中,我們可以看到右行的藍色是如何明顯過擬合的。
但是為什麼會這樣呢?
當試圖在新的、以前看不見的數據(即驗證/測試集)上評估我們的模型時,模型的性能將比我們預期的要差得多。
如何防止過擬合?
在帖子的開頭,我暗示您的模型的複雜性實際上是導致過度擬合的原因,因為它允許模型從訓練集中提取不必要的關係,從而映射其固有的噪聲。減少過度擬合的最簡單方法是從本質上限制模型的容量。這些技術稱為正則化技術。
- 參數規範懲罰。這些為每個模型的權重更新函數添加了一個額外的項,這取決於參數的範數。該術語的目的是對抗實際更新(即限制每個權重可以更新多少)。這使得模型對異常值和噪聲更加魯棒。此類正則化的示例是L1 和 L2正則化,可以在Lasso、Ridge和Elastic Net回歸器上找到。
由於神經網絡中的每個(完全連接的)層的功能很像簡單的線性回歸,因此這些都用於神經網絡。最常見的用途是分別對每一層進行正則化。
- 早停。這種技術試圖過早地停止估計器的訓練階段,在它學會從數據中提取所有有意義的關係之前,在開始對其噪聲進行建模之前。這是通過監控****驗證損失(或您選擇的驗證指標)並在該指標停止改進時****終止訓練階段來完成的。這樣,我們給估計器足夠的時間來學習有用的信息,但不足以從噪聲中學習。keras 實現。
神經網絡特定的正則化。一些例子是:
- 輟學。Dropout是一種有趣的技術,效果非常好。Dropout 應用於網絡中的兩個連續層之間。在每次迭代中,連接兩層的指定百分比的連接(隨機選擇)被丟棄。這導致後續層依賴於其與前一層的所有連接。
- 遷移學習。這特別用於深度學習。這是通過將網絡的權重初始化為另一個網絡的權重來完成的,該網絡具有在大型通用數據集上預訓練的相同架構。
- 其他可能限制深度神經網絡過度擬合的因素是:批量標準化,它可以作為一個調節器,在某些情況下(例如 inception 模塊)和 dropout 一樣有效;SGD 中相對**較小的批次**,也可以防止過擬合;在隱藏層的權重中添加小的隨機噪聲。
除了限制模型的容量之外,防止過度擬合的另一種方法是提高數據的質量。最明顯的選擇是去除異常值/噪聲,但實際上它們的用處有限。一種更常見的方式(尤其是在與圖像相關的任務中)是數據增強。在這裡,我們嘗試隨機變換訓練示例,以便在模型看來它們不同時,它們傳達相同的語義信息(例如,左右翻轉圖像)。
實用建議:
- 到目前為止,最有效的正則化技術是dropout,這意味著您應該首先使用它。但是,您不需要(也可能不應該)到處放置 dropout!最容易過擬合的層是全連接(FC)層,因為它們包含的參數最多。Dropout 應該應用於這些層(影響它們與下一層的連接)。
- 批量歸一化,除了具有正則化效果外,還可以通過其他幾種方式幫助您的模型(例如,加速收斂,允許使用更高的學習率)。它也應該在 FC 層中使用。
- 如前所述,在訓練階段比預定時間更早地停止模型也可能是有益的。提前停止的問題在於,無法保證在任何給定點上,模型都不會再次開始改進。比提前停止更實用的方法是存儲在驗證集上實現最佳性能的模型的權重。但是要小心,因為這不是對模型性能的無偏估計(只是比訓練集好)。您還可以在驗證集上過擬合。稍後再談。
- 在某些應用程序(例如與圖像相關的任務)中,強烈建議遵循已經建立的架構(例如 VGG、ResNet、Inception),您可以為其找到 ImageNet 權重。該數據集的通用性允許特徵反過來足夠通用以用於任何與圖像相關的任務。除了對過度擬合具有魯棒性外,這將大大減少訓練時間。
類似概念的另一種用法如下:如果您的任務沒有太多數據,但您可以找到另一個類似的任務,您可以使用遷移學習來減少過度擬合。首先針對具有較大數據集的任務訓練您的網絡,然後嘗試微調將模型設置為您最初想要的模型。在大多數情況下,初始訓練將使您的模型對過度擬合更加穩健。
- 數據增強。雖然擁有更大的數據集**總是有幫助的,但數據增強技術確實有其缺點。**更具體地說,您必須小心不要過於強烈地擴充,因為這可能會破壞數據的語義內容。例如,在圖像增強中,如果您過度平移/移動/縮放或調整圖像的亮度/對比度,您將丟失其中包含的大部分信息。此外,需要以特別的方式為每個任務實施增強方案(例如,在手寫數字識別中,數字通常是對齊的,不應該旋轉太多;也不應該向任何方向翻轉,因為它們不是水平/垂直對稱的。醫學圖像也是如此)。
簡而言之,注意不要通過數據增強產生**不真實的圖像。**此外,增加的數據集大小將需要更長的訓練時間。就個人而言,當我看到我的模型接近時,我開始考慮使用數據增強 $ 0 $ 訓練集上的損失。